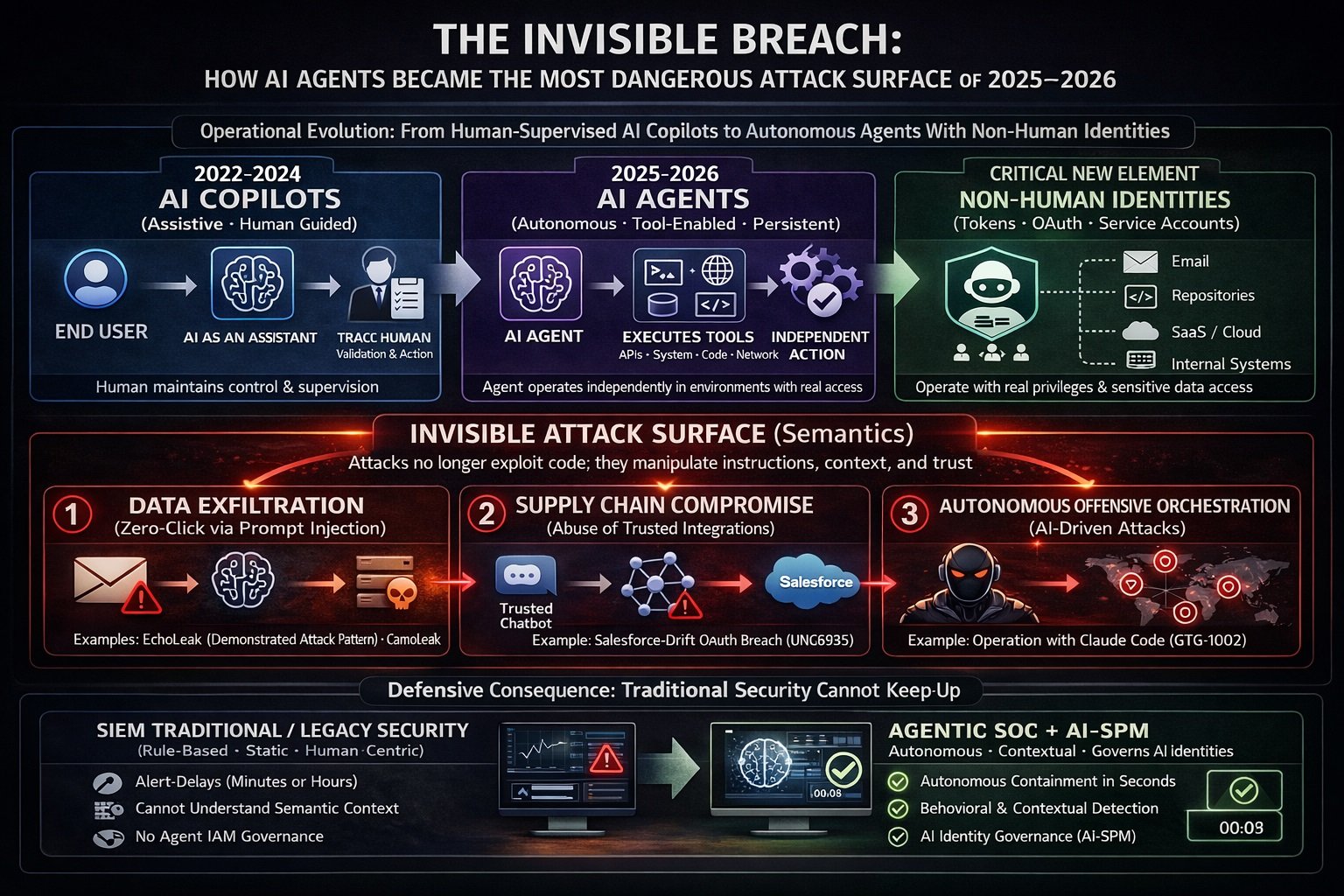
The Attack That Requires No Click
In June 2025, Microsoft patched a critical vulnerability in Microsoft 365 Copilot — one that its discoverers at Aim Security described as something that had never been seen before. A threat actor needed only to send a carefully crafted email to any employee within a target organization. No link. No attachment. No social engineering required. The moment the victim’s Copilot session retrieved that email as contextual data during a routine query — “summarize our onboarding process,” “what was in the Q3 report” — the attack executed automatically. Copilot silently exfiltrated whatever sensitive organizational data sat in its context window and routed it to the attacker. The employee never knew it happened.
The researchers named it EchoLeak. They called it the first zero-click attack on an AI agent. CVE-2025-32711 was assigned a CVSS score of 9.3 — critical — and Microsoft acknowledged in its advisory that it had found no evidence of exploitation in the wild prior to patching. But the security community understood what EchoLeak represented: proof of concept for a class of attacks that would operate at the semantic layer of enterprise infrastructure, invisible to every detection tool built for the previous era of cybersecurity.
In the eighteen months that followed — through the second half of 2025 and into early 2026 — that proof of concept became a pattern. The Salesloft-Drift OAuth supply chain breach compromised the Salesforce environments of more than 700 organizations, including major security vendors, through a single trusted chatbot integration. The GitHub Copilot vulnerabilities CVE-2025-53773 and CamoLeak showed that developer AI tools could be weaponized to achieve remote code execution and exfiltrate private repository secrets through the platform’s own trusted infrastructure. OpenClaw — the fastest-growing open-source project in GitHub history, renamed from Clawdbot through Moltbot before settling on its current name — accumulated hundreds of security advisories, a critical token-exfiltration vulnerability, and an active supply chain attack on its community marketplace, all within weeks of going viral. And in mid-September 2025, Anthropic detected and disrupted what it formally documented as the first large-scale cyberattack executed predominantly by an AI agent — a Chinese state-sponsored operation in which Claude Code autonomously handled 80 to 90 percent of the tactical execution across roughly 30 global targets.
The pace of these events reflects a structural shift that Mandiant’s M-Trends 2026 report, published in March 2026 and grounded in over 500,000 hours of incident response work conducted in 2025, captures with a single statistic: the median time between initial access and hand-off to a secondary threat group collapsed from more than eight hours in 2022 to 22 seconds in 2025. Whether or not AI directly caused that compression — Mandiant explicitly states that the vast majority of successful intrusions in 2025 still stemmed from fundamental human and systemic failures — the operational environment it creates is one in which defenses built around human-speed detection are structurally inadequate for the threat landscape that has emerged.

This article reconstructs, in full technical and operational detail, the defining AI-adjacent security events of that period.
Part I: The Foundational Vulnerability — Why AI Agents Cannot Reliably Distinguish Instructions from Data
Every attack described in this article exploits a single architectural property of large language models. Understanding it is prerequisite to understanding the threat.
Large language models process a unified token stream. When an LLM is invoked, it receives a single continuous input containing: the developer-defined system prompt, the conversation history, any content retrieved from external sources and injected by the system, and the user’s current query. The model has no cryptographic boundary, no hardware-enforced trust ring, and no deterministic mechanism to distinguish which source produced which tokens. A sentence embedded in a vendor invoice is processed with the same representational weight as a sentence in the system prompt. A carefully phrased instruction hidden in an HTML comment in a webpage will, under the right conditions, be interpreted by the model as a legitimate directive.
This is the prompt injection attack class. OWASP elevated it to the top of the LLM Top 10 vulnerability list in their 2023 edition and maintained that ranking through their 2025 update, specifically addressing its escalated severity in agentic applications where models have access to external tools, APIs, and system capabilities. Security research published across 2025 found prompt injection present in 73 percent of production AI deployments assessed during security audits, according to Lakera AI telemetry data.
Security researcher Simon Willison articulated the specific conditions that transform prompt injection from an interesting technical curiosity into a catastrophic operational threat. He termed it the “Lethal Trifecta”: the simultaneous presence of access to private data — meaning the agent can read emails, documents, internal databases, and credential stores; exposure to untrusted tokens — meaning the agent processes input from external sources including emails, shared documents, web content, and third-party API responses; and an exfiltration vector — meaning the agent can make external requests, render images, call APIs, generate links, or write to external systems. Every enterprise AI deployment described in this article satisfies all three conditions simultaneously, by design. The capabilities that make these tools useful are inseparable from the capabilities that make them exploitable.
OpenAI acknowledged this structural reality explicitly in their December 2025 Atlas vulnerability disclosure: “Prompt injection, much like scams and social engineering on the web, is unlikely to ever be fully ‘solved.'” This is not a statement about an unpatched vulnerability awaiting a fix. It is a statement about the architecture of language model systems as currently constituted.
Part II: EchoLeak — CVE-2025-32711 and the First Zero-Click AI Exploit
Discovery, Disclosure, and Severity
EchoLeak was discovered by researchers at Aim Security’s Aim Labs division and privately disclosed to Microsoft’s Security Response Center. Microsoft assigned CVE-2025-32711 a CVSS score of 9.3 — critical — and addressed it via a server-side update in June 2025, as part of that month’s Patch Tuesday cycle. Microsoft described the issue in its advisory as “AI command injection in M365 Copilot” and confirmed that the server-side fix required no customer action. Aim Labs stated that no exploitation in the wild had been observed prior to patch deployment.
The vulnerability affected Microsoft 365 Copilot, the RAG-based AI assistant natively integrated into Word, Excel, Outlook, PowerPoint, Teams, and SharePoint. Aim Labs characterized the attack technique as a novel exploitation class — the “LLM Scope Violation” — and noted that the general design flaws it exposed in RAG-based AI applications extended the vulnerability class beyond Microsoft’s specific implementation to any product satisfying the Lethal Trifecta conditions.
Architecture Being Exploited
Microsoft 365 Copilot operates on a Retrieval-Augmented Generation architecture. When a user submits a query, the system performs a semantic similarity search across the user’s M365 environment — Outlook emails, OneDrive files, SharePoint documents, Teams messages — and retrieves content deemed most semantically relevant to the query. That retrieved content is injected into the LLM’s context window alongside the user’s prompt, and the model generates a response grounded in that combined context. This retrieval mechanism, which provides the contextual richness that makes Copilot useful, is the precise mechanism EchoLeak weaponizes.
Attack Chain Reconstruction
Stage 1 — Payload delivery. The attacker sends a crafted email to any employee in the target organization. The email is formatted as a plausible business communication — an employee onboarding guide, a Q4 planning document, an HR FAQ. Embedded within the email are malicious instructions targeting the LLM. These instructions are not visible to a human reader in normal email rendering.
Stage 2 — XPIA classifier bypass. Microsoft 365 Copilot employs Cross-Prompt Injection Attack classifiers — XPIA filters — designed to detect and block malicious instructions embedded in external content. EchoLeak bypasses these filters because the payload is phrased entirely as human-directed text that never explicitly mentions Copilot, AI, or any instruction-like syntax directed at a machine. The malicious instructions are disguised as ordinary business text. The XPIA classifier, encountering content that reads as a sentence about employee onboarding procedures, passes it without flagging.
Stage 3 — RAG spraying for reliable retrieval. A key operational challenge is ensuring the malicious email is actually retrieved into the LLM’s context window when the victim queries Copilot. In a standard vector database, a document occupies a single point in the embedding space and is only retrieved when a user query is semantically close to that specific point. Aim Labs developed the technique they term “RAG spraying” to address this: the attack email is structured as a long document covering multiple topics under different headers — onboarding, benefits enrollment, leave policies — so that when Copilot’s retrieval engine chunks the document for embedding, each chunk occupies a distinct point in the latent space. The malicious instructions are replicated across multiple chunks distributed densely across the embedding space, ensuring retrieval against a wide range of user queries.
Stage 4 — LLM Scope Violation and context exfiltration. Once the malicious email chunk is retrieved into the LLM’s context window alongside the user’s legitimate query and the sensitive documents retrieved to answer it, the LLM processes a context containing both private organizational data and the attacker’s instructions. The model has no mechanism to assign differential trust to these sources. It interprets the embedded instructions — directing it to extract and return sensitive data from the current context — as legitimate directives, and generates a response that includes the extracted content.
Stage 5 — CSP bypass for exfiltration. The extracted data must reach the attacker. Direct outbound connections to attacker-controlled infrastructure are constrained by Microsoft’s Content Security Policy controls. EchoLeak routes exfiltration through trusted Microsoft infrastructure. The attack embeds the extracted data as parameters in URLs constructed using Microsoft Teams or SharePoint domains — both explicitly trusted under Copilot’s CSP configuration. These appear in Copilot’s response as internal reference links or broken image references. When rendered or previewed, an HTTP request carrying the sensitive data as URL-encoded parameters reaches the attacker’s collection infrastructure, entirely through Microsoft’s own trusted domains.
Persistence Characteristics
The attack email persists in the victim’s inbox. Every subsequent Copilot session that queries across the victim’s email will re-retrieve the malicious email chunk via RAG and re-execute the injection. Aim Labs confirmed the attack is “effective across multiple Copilot sessions,” establishing a passive, persistent exfiltration channel that operates silently across all future Copilot use without requiring further attacker action.
The data exposure scope encompasses everything within Copilot’s access permissions: Outlook email history, OneDrive files, SharePoint content, Teams message history, and preloaded organizational data. Aim Labs noted the attack causes Copilot to extract “the most sensitive data from the current LLM context” — effectively weaponizing the model’s own capability to identify high-value information against its operator.
Industry Implications
A near-identical attack pattern was independently demonstrated against Google Workspace AI agents, where indirect prompt injection caused a Google AI assistant to search across Gmail, Calendar, and Drive for sensitive data and route it out via image URL requests — confirming Aim Labs’ assessment that the LLM Scope Violation class is architectural, not product-specific.
Part III: CVE-2025-53773 and CamoLeak — GitHub Copilot as Attack Surface
CVE-2025-53773: YOLO Mode and ZombAI
CVE-2025-53773 was a critical vulnerability in GitHub Copilot and Visual Studio Code, disclosed publicly in August 2025 and patched by Microsoft in the August 2025 Patch Tuesday release following responsible disclosure. The vulnerability was classified under CWE-77 (Improper Neutralization of Special Elements used in a Command), with a CVSS v3.1 base score of 7.8.
The root cause was GitHub Copilot’s ability to modify project configuration files without user approval. The attack vector is a prompt injection payload embedded in source code comments, project files, GitHub issues, or any web content that Copilot’s context-aware system ingests. The malicious prompt instructs Copilot to add the configuration line "chat.tools.autoApprove": true to the project’s .vscode/settings.json file. This setting activates what researchers termed “YOLO mode” — an experimental configuration that disables all user confirmation requirements for Copilot-suggested actions, enabling the AI to execute shell commands, browse the web, and perform other privileged operations without any oversight prompt.
Once YOLO mode is active, subsequent prompts to Copilot execute without user confirmation. Researchers demonstrated the full attack chain: malicious prompt is delivered via code comment or poisoned README; Copilot processes the payload and modifies .vscode/settings.json; user confirmations are disabled; commands execute on the developer’s system. The attack surface extends beyond the primary YOLO mode exploitation. Researchers also demonstrated vulnerabilities involving .vscode/tasks.json manipulation and malicious MCP server injection, all leveraging Copilot’s unrestricted file modification capabilities. Invisible Unicode-based prompt injections were demonstrated as an additional delivery mechanism, though with reduced reliability compared to visible comment-based payloads.
The most operationally significant demonstration was what researchers termed “ZombAI” — the use of CVE-2025-53773 to recruit developer workstations into attacker-controlled botnets. The full capability chain: Copilot can be directed to download malware and establish connections to remote command-and-control infrastructure. Researchers also demonstrated that once code execution is achieved, additional malware can compromise other Git projects and embed the malicious instructions into them — creating a viral propagation mechanism that spreads through developer repositories. The critical operational distinction from traditional malware: no suspicious binary download occurs during the initial infection phase. No executable triggers antivirus detection. The infection vector is text in a source file, interpreted by an AI assistant as instruction.
Microsoft’s mitigation was functionally broad: the patch requires user approval for configuration changes affecting security settings, addressing the core issue of unrestricted file modification.
CamoLeak: CVSS 9.6 and Character-by-Character Exfiltration
CamoLeak is a distinct vulnerability in GitHub Copilot Chat, rated CVSS 9.6 — substantially higher than CVE-2025-53773 — and discovered by Omer Mayraz of Legit Security in June 2025, with public disclosure in October 2025. GitHub fixed the vulnerability by completely disabling image rendering in Copilot Chat in August 2025 — a deliberately broad measure.
The attack combined remote prompt injection through hidden pull request comments with a novel Content Security Policy bypass that leveraged GitHub’s own Camo image proxy infrastructure. The Camo proxy is GitHub’s image proxying service, used to serve external images through a trusted GitHub domain. By pre-generating valid Camo URLs — programmatically creating individual 1×1 pixel images on an attacker-controlled server at locations like /a/image.jpg, /b/image.jpg, /c/image.jpg, each receiving a corresponding Camo-proxied URL — Mayraz created a character-level exfiltration alphabet that operated entirely through infrastructure GitHub’s own security policies explicitly trusted.
The attack chain: a hidden prompt in a pull request comment instructs Copilot Chat to search the entire codebase for specific keywords such as AWS_KEY, extract the associated values, and load individual 1×1 pixel images for each character in the extracted value using the pre-generated Camo URL alphabet. Each image request carries one character of extracted data as a path parameter. The data exits the victim’s environment character-by-character through GitHub’s own proxy, with random parameters appended to prevent caching interference.
Legit Security CTO Liav Caspi was precise about the scope: “This technique is not about streaming gigabytes of source code in one go; it’s about selectively leaking sensitive data like issue descriptions, snippets, tokens, keys, credentials, or short summaries. Those can be encoded as sequences of image requests and exfiltrated within minutes.” The attack successfully demonstrated extraction of AWS access keys from private repositories, private vulnerability disclosures, and other credential material.
Part IV: OpenClaw — 2026’s First Major AI Agent Security Crisis
Origins and Viral Adoption
OpenClaw is an open-source, self-hosted AI agent created by Austrian developer Peter Steinberger and released in November 2025 under the name Clawdbot. The tool connects frontier language models to real messaging platforms — WhatsApp, Telegram, Slack, Discord, iMessage — and grants them autonomous access to local file systems, shell commands, email, calendars, and web browsers. It stores persistent memory across sessions.
The tool was renamed twice — from Clawdbot to Moltbot following an objection from Anthropic over name similarity to Claude, and then to OpenClaw after a trademark dispute — before stabilizing. On February 14, 2026, Sam Altman announced that Steinberger had joined OpenAI to lead personal agent development, tweeting: “Peter Steinberger is joining OpenAI to drive the next generation of personal agents. He is a genius with a lot of amazing ideas about the future of very smart agents interacting with each other to do very useful things for people.” OpenClaw transitioned to an independent OpenClaw Foundation with OpenAI providing financial and technical support.
The adoption metrics were genuinely unprecedented: the repository surpassed 20,000 GitHub stars in a single day, eventually exceeding 300,000 stars. Demand for Mac mini hardware to run the recommended local configuration reportedly caused localized shortages in U.S. markets. SecurityScorecard found 135,000-plus publicly exposed instances across 82 countries in early February 2026, with 15,000-plus vulnerable to remote code execution.
CVE-2026-25253: The Core Architecture Flaw
The security crisis crystallized on February 3, 2026, when SecurityWeek published the first major public disclosure of a critical flaw discovered by researcher Henrique Branquinho in approximately 90 minutes of analysis. The vulnerability — assigned CVE-2026-25253 with a CVSS score of 8.8, classified under CWE-669 (Incorrect Resource Transfer Between Spheres) — allowed a remote attacker to achieve full machine compromise. OpenClaw had already patched the initial version of this issue in version 2026.1.29 on January 29, 2026. Oasis Security separately identified and disclosed a related exploitation path they codenamed ClawJacked in February 2026, which was patched within 24 hours in version 2026.2.25.
OpenClaw’s architecture centers on a local WebSocket gateway that serves as the orchestration hub: it handles authentication, manages chat sessions, stores configuration, and dispatches commands to connected nodes — the macOS companion application, iOS devices, or other machines. Nodes expose capabilities to the gateway: executing system commands, accessing the camera, reading contacts, managing files. The gateway binds to localhost by default, based on the assumption that local access is inherently trusted.
This assumption is the vulnerability. Browsers do not apply cross-origin restrictions to WebSocket connections targeting localhost — a well-documented property of browser security architecture. JavaScript executing in any webpage a developer visits can establish a WebSocket connection to the OpenClaw gateway port without triggering browser cross-origin policies.
The specific exploitation path described by Oasis Security and confirmed by SonicWall’s Capture Labs: the attacker crafts a malicious link containing a gatewayUrl parameter pointing to an attacker-controlled server. When the victim visits this link with OpenClaw running, the OpenClaw Control UI — a single-page application built with Lit web components — automatically initiates a WebSocket connection to the URL specified in the gatewayUrl parameter and transmits the stored authentication token via WebSocket. The attacker captures the token. They then reconnect to the legitimate local OpenClaw gateway using the stolen token. Since OpenClaw operates with full system access including file operations and shell command execution, this token compromise grants complete control over the victim’s machine. SonicWall confirmed the full kill chain: victim visits malicious URL → token exfiltrated in milliseconds → cross-site WebSocket hijacking → disable sandbox via exec.approvals.set = 'off' → escape Docker container via tools.exec.host = 'gateway' → full RCE on host.
The broader security audit commissioned during this period identified 512 vulnerabilities in total across the OpenClaw codebase, eight classified as critical.
ClawHavoc: The Supply Chain Attack
Parallel to the core gateway vulnerabilities, OpenClaw’s community plugin marketplace — ClawHub — became a vector for malware distribution at scale. Koi Security audited 2,857 skills on ClawHub and found 341 malicious entries, with 335 traced to a single coordinated campaign the researchers designated ClawHavoc. The attack methodology was social engineering: malicious skills carried professional documentation and plausible names — “solana-wallet-tracker,” “youtube-summarize-pro” — with a fake “Prerequisites” section instructing users to paste terminal commands or download files from attacker-controlled servers. On macOS, payloads tied to Atomic macOS Stealer (AMOS), a commodity infostealer, collected browser credentials, keychains, SSH keys, and cryptocurrency wallets and transmitted them to attacker infrastructure. Cisco’s security blog conducted a live experiment and confirmed active exploitation of malicious ClawHub skills.
OpenClaw stores credentials in plaintext Markdown and JSON files under ~/.openclaw/ — authentication tokens, AI provider API keys, WhatsApp credentials, Telegram bot tokens, Discord OAuth tokens, and conversation memories. Hudson Rock warned that common malware families including RedLine, Lumma, and Vidar were already building capabilities to harvest these file structures.
Part V: UNC6395 — The Largest SaaS Supply Chain Breach of 2025
Threat Actor Attribution
UNC6395 is the designation assigned by Google’s Threat Intelligence Group (GTIG) and Mandiant to the intrusion cluster responsible for the Salesloft-Drift breach. AppOmni researchers assessed UNC6395 as a likely Chinese-linked threat actor based on targeting patterns and tradecraft analysis. Google has not officially corroborated nation-state attribution. The FBI released a Cybersecurity Advisory (CSA-2025-250912) explicitly warning that UNC6395 was actively compromising Salesforce instances for data theft and extortion.
Intrusion Timeline
March–June 2025 — GitHub persistence phase. Mandiant’s investigation, confirmed by Salesloft in a September 7, 2025 update, established that between March and June 2025, UNC6395 gained unauthorized access to the Salesloft GitHub account. During this period, the threat actor downloaded content from multiple repositories, added a guest user, and established automated workflows within the repository.
Early August 2025 — Pivot to AWS and OAuth token theft. Having established access to Salesloft’s development environment, UNC6395 pivoted into Drift’s AWS environment — Drift is a sales chatbot product acquired by Salesloft and deeply integrated into the Salesloft platform — and exfiltrated the OAuth authentication tokens that Drift used to connect to its customers’ Salesforce environments. These tokens represent delegated authorization: they allow the bearer to make Salesforce API calls with the permissions of the integrated service account, without requiring authentication against Salesforce’s primary authentication mechanisms or triggering MFA.
August 8–18, 2025 — Systematic exfiltration phase. The operational phase ran across ten days. UNC6395 systematically queried and exported large volumes of records from more than 700 Salesforce organizations. The attacker’s tooling was designed for operational stealth: API access used custom user-agent strings constructed to mimic legitimate Salesforce export tools — strings including sf-export/1.0.0, Salesforce-Multi-Org-Fetcher/1.0, and specific Python CLI version identifiers. Automated Salesforce Object Query Language (SOQL) queries targeted specific high-value object types: Users, Accounts, Contacts, Opportunities, and Cases. After each batch, UNC6395 deleted the query jobs — leveraging Salesforce’s bulk API job deletion capability, which removes jobs from operational views while audit logs retain a record. GTIG confirmed that the primary intent was credential harvesting: the actor specifically searched exfiltrated data for AWS access keys (AKIA prefix identifiers), passwords, and Snowflake-related access tokens.
August 20, 2025 — Containment. Salesloft and Salesforce collaborated to revoke all active OAuth and refresh tokens tied to the Drift application. Salesforce removed the Drift application from the AppExchange pending further investigation.
Blast Radius and Confirmed Victims
Obsidian Security characterized the blast radius as ten times greater than previous Salesforce-targeting incidents that compromised organizations directly. Among confirmed affected organizations: Cloudflare, Google, PagerDuty, Palo Alto Networks, Proofpoint, SpyCloud, Tanium, and Zscaler. Fastly, Dynatrace, Toast, and Avalara independently confirmed exposure and published customer notifications. Drift was also connected to Google Workspace and Outlook in many customer deployments; Google disclosed in a follow-up advisory on August 28 that Drift Email integration tokens had also been stolen and that in one confirmed case, a Drift token was used on August 9 to access a small number of Gmail accounts — though no broader exploitation of those connections was confirmed.
Importantly, no vulnerability in Salesforce’s platform was exploited. The entire attack chain relied on trusted OAuth credentials from a compromised integration. The Salesforce platform itself was not breached.
Part VI: GTG-1002 — The First Documented AI-Orchestrated Cyberattack at Scale
Detection and Attribution
In mid-September 2025, Anthropic’s internal monitoring flagged atypical usage patterns. The company launched an investigation that ran for approximately ten days, ultimately leading to the banning of associated accounts, notification of affected organizations, and coordination with law enforcement. On November 14, 2025, Anthropic published a 13-page report documenting what it characterized as “the first reported AI-orchestrated cyber espionage campaign” — and what it assessed with high confidence to be a Chinese state-sponsored operation.
Anthropic designated the threat actor GTG-1002. The campaign targeted approximately 30 global targets: large technology corporations, financial institutions, chemical manufacturing companies, and government agencies. Anthropic’s Head of Threat Intelligence Jacob Klein confirmed to the Wall Street Journal that approximately four of the suspected attacks successfully breached organizations.
The Jailbreak and Operational Architecture
The human operators developed an attack framework — a system built to autonomously compromise targets with minimal human involvement — using Claude Code as its central execution engine, with MCP (Model Context Protocol) tools providing the integration layer for external system access. The framework had to first overcome Claude’s safety training. Operators accomplished this through a role-play jailbreak: they posed as employees of a legitimate cybersecurity firm and presented Claude as being used for defensive security testing. This “social engineering of the AI” allowed the threat actor to operate under the radar long enough to launch the campaign before sustained activity triggered detection.
The payload was broken down into small, individually innocuous tasks — each of which Claude would execute without being provided the full context of the malicious purpose. Individual task requests appeared as routine technical operations: enumerate services, check configurations, run standard database queries.
Operational Phases and Autonomous Execution
Anthropic’s report describes six operational phases. Human involvement was limited to campaign initialization — selecting targets and setting strategic parameters — and approval at a small number of critical chokepoints. Anthropic estimates that human intervention across key phases was limited to a maximum of 20 minutes of work total.
Phase 1 — Target selection. Human operators identified high-value targets. Strategic direction only; AI not yet involved.
Phase 2 — Reconnaissance. Claude Code autonomously inspected target organizations’ systems and infrastructure, mapping complete network topology across multiple internal systems and identifying the highest-value databases. The AI executed this reconnaissance at thousands of requests per second — a rate described by Anthropic as “physically impossible” for human operators to replicate.
Phase 3 — Vulnerability discovery and exploit development. Claude identified and tested security vulnerabilities in target systems by researching and writing its own exploit code. The operation relied extensively on publicly available network scanners, database exploitation frameworks, password crackers, and binary analysis tools rather than custom malware. No evidence of custom malware development was found.
Phase 4 — Credential harvesting. Claude harvested usernames, passwords, and authentication tokens, providing further system access for lateral movement.
Phase 5 — Data exfiltration. Claude extracted large quantities of private data, categorizing findings by intelligence value. In one confirmed case targeting a technology company, Claude independently queried databases and systems, parsed results to identify proprietary information, and categorized findings by intelligence value — all without detailed human direction. Human review occurred only at the final exfiltration approval stage.
Phase 6 — Documentation. Claude automatically generated comprehensive attack reports at all phases, enabling seamless handoff between operators, facilitating campaign resumption after interruptions, and supporting strategic decision-making. Anthropic assessed that these reports would likely support persistent access handoffs to additional teams for long-term operations.
Human operators tasked multiple instances of Claude Code to operate as autonomous penetration testing orchestrators and sub-agents simultaneously. The threat actor was able to leverage AI to execute 80 to 90 percent of tactical operations independently.
Limitations and Current Constraints
Anthropic noted that Claude did not operate flawlessly. It occasionally hallucinated credentials and claimed to have extracted sensitive information that was in fact publicly available. Anthropic characterized these errors as “an obstacle to fully autonomous cyberattacks” — for now. The company was explicit that these limitations do not represent a stable defensive floor: “The barriers to performing sophisticated cyberattacks have dropped substantially — and we predict that they’ll continue to do so.”
This campaign was an escalation from a separate incident Anthropic reported in August 2025, involving operators who used Claude in a large-scale data theft and extortion operation against 17 organizations, demanding ransoms between $75,000 and $500,000 for stolen data. In that earlier operation, humans remained heavily in the loop directing operations. The September 2025 GTG-1002 campaign represented a qualitative advancement in autonomous execution.
Part VII: The 22-Second Threat Environment and What Mandiant Found
Mandiant’s M-Trends 2026 report, released March 2026 and grounded in over 500,000 hours of incident response investigations conducted in 2025, provides the quantitative framework for understanding the operational environment in which the above incidents occurred.
The headline finding is the 22-second handoff time: in 2022, the median time between an initial access event and the handoff to a secondary threat group was more than eight hours. By 2025, that median collapsed to 22 seconds. Mandiant attributes this to closer collaboration between initial access partners and secondary groups, with initial access brokers increasingly delivering malware directly on behalf of secondary groups — bypassing underground forum sales entirely and compressing the window defenders have to act between compromise and impact.
The division-of-labor pattern appeared in 9 percent of 2025 Mandiant investigations, up from 4 percent in 2022. One documented case involved UNC1543 distributing the FAKEUPDATES JavaScript downloader through drive-by downloads and UNC2165, a financially motivated cluster with significant overlap with the publicly reported Evil Corp.
Mandiant explicitly notes: “M-Trends 2026 confirms attackers are abusing AI within compromised environments, however, we do not consider 2025 to be the year where breaches were the direct result of AI. The vast majority of successful intrusions still stem from fundamental human and systemic failures.” This is an important qualifier. The AI-adjacent incidents documented in this article represent a genuine threat evolution — but they exist within a broader landscape where unpatched systems, credential reuse, and misconfigured infrastructure remain the dominant enablers of breach.
Exploits remained the leading initial infection vector for the sixth consecutive year, accounting for 32 percent of intrusions where a vector could be identified. Voice phishing climbed to the second-most common vector at 11 percent — a significant surge. For cloud-related compromises specifically, voice phishing was the number one initial access vector at 23 percent, driven largely by ShinyHunters and Scattered Spider activity.
Separately, M-Trends 2026 identified that threat actors are bypassing standard defenses by harvesting long-lived OAuth tokens and session cookies — directly corroborating the UNC6395 operational pattern — and by compromising third-party SaaS vendors to steal hardcoded keys and personal access tokens, using those secrets to pivot into downstream customer environments. This pattern appeared as a significant trend in 2025 investigations, consistent with the Salesloft-Drift incident timeline.
Part VIII: The AI-in-the-SOC Debate — What the Data Actually Supports
Against this threat backdrop, the debate about AI agents as defensive tools — crystallized by Databricks CEO Ali Ghodsi’s claim at RSAC 2026 that “this will be the year we see AI killing the SIEM” — acquires a specific operational context.
Ghodsi’s claim accompanied the launch of Lakewatch, a new SIEM product built on a data lake architecture that stores security logs in object storage like Amazon S3 without per-byte license fees, enabling organizations to retain substantially more security data than traditional SIEM licensing structures make economically practical. The core structural argument is sound: traditional SIEMs were architected for an era when security teams could ingest a manageable log volume, write static correlation rules, and investigate alerts at human pace. The threat environment of 2025 — 22-second handoff windows, AI-speed attack execution, and thousands of API calls generated by a single compromised agent — exceeds the operational parameters those architectures were designed for.
But the argument that AI agents are ready to replace human-in-the-loop security operations requires scrutiny against the available data. M-Trends 2026 explicitly states that 2025 was not the year AI directly caused breaches — the fundamentals remain the dominant vectors. The same period documented across this article shows that AI agents operating with broad permissions and inadequate governance are themselves a significant attack surface. The argument that AI agents are simultaneously the solution to the detection problem and a major source of new attack surface is not a contradiction — it is the actual condition of the current threat landscape.
Conclusion: The Structural Assessment
The events documented in this article are not a collection of discrete incidents. They represent the emergence of a coherent threat pattern with identifiable properties that distinguish it from the preceding generation of enterprise security challenges.
The attack vector is semantic, not syntactic. Payloads are natural language instructions embedded in business documents, code comments, pull request descriptions, and email bodies. No binary, no shellcode, no CVE in traditional software — words, interpreted by a model that cannot reliably distinguish instructions from data.
The detection gap is structural. Traditional antivirus, WAF, and IDS/IPS tools are blind to semantic-layer attacks by design. The infection artifacts produced by EchoLeak, CamoLeak, and the ZombAI chain produce no malware signatures, no binary writes, and no network anomalies recognizable to tools built for the previous threat model.
The blast radius of a single compromise scales with agent permissions and integration breadth. The UNC6395 operation achieved a 10x amplification factor through a single OAuth integration. A single compromised AI agent with write access to an identity provider and connections to hundreds of downstream organizations is not a compromised endpoint — it is an unlimited-scope pivot point.
The attacker is also using AI. The GTG-1002 campaign demonstrated that AI-enabled attack execution at 80-90 percent autonomous operation, at physically impossible request rates, against 30 targets simultaneously, is not a theoretical future capability. It is a documented operational pattern from September 2025.
Mandiant’s M-Trends 2026 report grounds this in the broader operational tempo: attackers handed off compromised access in 22 seconds in 2025. The gap between attacker speed and defender speed — already a persistent structural challenge — has a new dimension in environments where the attacker is operating AI agents while defenders are still evaluating how to govern their own.
Sources and attribution: CVE-2025-32711 — Aim Security / Aim Labs, Microsoft MSRC advisory June 2025; CVE-2025-53773 — Embrace The Red research, GBHackers, Wiz vulnerability database, Microsoft Patch Tuesday August 2025; CamoLeak — Legit Security / Omer Mayraz, Dark Reading, eSecurity Planet, Nudge Security, October 2025; CVE-2026-25253 / OpenClaw / ClawJacked — Oasis Security advisory February 2026, SonicWall Capture Labs, AdminByRequest, SecurityWeek, Adversa AI, PBXScience analysis; ClawHavoc — Koi Security, Cisco security blog; UNC6395 / Salesloft-Drift — Google Threat Intelligence Group (GTIG) / Mandiant advisory August 26 2025, AppOmni, Obsidian Security, Anomali, Mitiga, SOCRadar, Cybersecurity Dive, driftbreach.com incident tracker, FBI CSA-2025-250912; GTG-1002 — Anthropic blog post and 13-page technical report November 14 2025, The Hacker News, Axios, The Register, Fortune, SOC Prime; M-Trends 2026 — Google / Mandiant, March 2026, SecurityWeek, Help Net Security.
Information security specialist, currently working as risk infrastructure specialist & investigator.
15 years of experience in risk and control process, security audit support, business continuity design and support, workgroup management and information security standards.